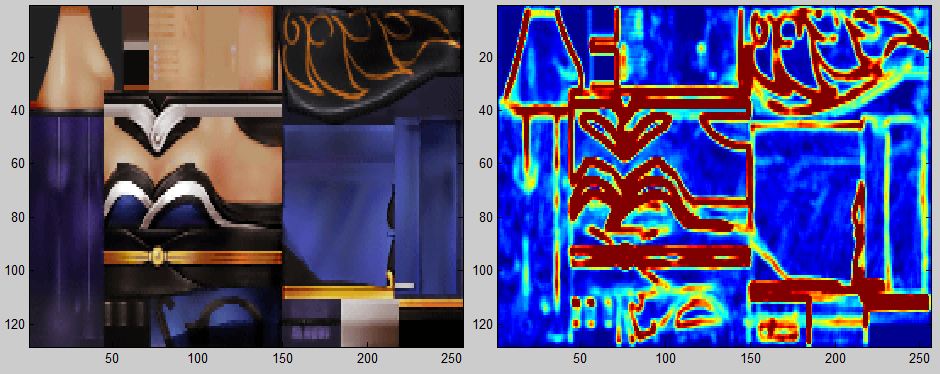
DSfix was based on a Direct3D9 wrapper, which was mostly taken from an existing code base and extended manually.
Recently, I’ve needed to hook Direct3D9Ex, and came to the conclusion that the manual busy work of writing the initial wrapper is better left to a computer than a human. Therefore, I wrote a Ruby script which takes a Microsoft COM dll header interface specification, and generates the C++ code for a wrapper class for it.
Here’s the script (wrapper_gen.rb), it’s rather tiny:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
# parameter check if(ARGV.size < 3 || ARGV.size > 4) puts "Usage: ruby wrapper_gen.rb INTERFACE_NAME IN_FILE_NAME OUT_NAME [LOG?]" puts "Examples: " puts " - ruby wrapper_gen.rb IDirect3DTexture9 d3d9.h d3d9tex" puts " produces d3d9tex.h and d3d9tex.cpp with no logging" puts " - ruby wrapper_gen.rb IUnknown d3d9.h unknown true" puts " produces unknown.h and unknown.cpp" puts " and adds logging to generated wrapper methods" puts "wrapper_gen version 0.2" exit(0) end # parameters interface_name = ARGV[0] file_name = ARGV[1] out_name = ARGV[2] logging = ARGV.size > 3 && ARGV[3] != "false" # logging spec log_string_pre = 'SDLOG(20, "' log_string_post = '\n");' # regexps used for input file parsing interface_exp = /DECLARE_INTERFACE_\(\s*#{interface_name}\s*,\s*(\w+)\s*\)\s*\{([^}]*)\s*};/m method_exp1 = /STDMETHOD\s*\(\s*(\w+)\s*\)\(([^)]+)\)/ method_exp2 = /STDMETHOD_\s*\(\s*(\w+)\s*,\s*(\w+)\s*\)\(([^)]+)\)/ param_exp = /^(.+?)\s+(\w+)$/ # used to write header to h and cpp files def write_header(file, iname, fname) file.puts "// wrapper for #{iname} in #{fname}" file.puts "// generated using wrapper_gen.rb" file.puts "" end # do stuff f = IO.binread(file_name) decl = interface_exp.match(f) if(!decl) puts "Could not find declaration of interface #{interface_name} in #{file_name}" exit(0) end File.open("#{out_name}.h", "w+") { |hfile| File.open("#{out_name}.cpp", "w+") { |cppfile| write_header(hfile, interface_name, file_name) hfile.puts "#include \"#{file_name}\"" hfile.puts "" hfile.puts "interface hk#{interface_name} : public #{interface_name} {" hfile.puts " #{interface_name} *m_pWrapped;" hfile.puts " " hfile.puts "public:" hfile.puts " hk#{interface_name}(#{interface_name} **pp#{interface_name});" hfile.puts " " hfile.puts " // original interface" write_header(cppfile, interface_name, file_name) cppfile.puts "#include \"#{out_name}.h\"" cppfile.puts "" cppfile.puts "hk#{interface_name}::hk#{interface_name}(#{interface_name} **pp#{interface_name}) {" cppfile.puts " m_pWrapped = *pp#{interface_name};" cppfile.puts " *pp#{interface_name} = this;" cppfile.puts "}" decl[2].each_line do |line| m1 = method_exp1.match(line) m2 = method_exp2.match(line) if(m1 || m2) # header l = line.strip.gsub(/,(\S)/,', \1').gsub(" PURE","").gsub("PURE","") l = l.gsub("THIS_ ", "").gsub("THIS", "") hfile.puts " #{l}" # parse name = m1 ? m1[1] : m2[2] rettype = m2 ? m2[1] : "HRESULT" param_string = m1 ? m1[2] : m2[3] params = param_string.split(",") params.reject! {|p| p.downcase == "this" } params.map! {|p| p.gsub("THIS_ ", "").strip } pnum = 0 params_split = params.map do |p| m = param_exp.match(p) if(m) [m[1], m[2]] else pnum += 1 [p, "param_#{pnum}"] end end param_string = params_split.map { |pair| "#{pair[0]} #{pair[1]}" }.join(", ") # cpp cppfile.puts "" cppfile.puts "#{rettype} APIENTRY hk#{interface_name}::#{name}(#{param_string}) {" cppfile.puts " #{log_string_pre}hk#{interface_name}::#{name}#{log_string_post}" if logging cppfile.puts " return m_pWrapped->#{name}(#{params_split.map {|p| p[1]}.join(", ")});" cppfile.puts "}" end end hfile.puts "};" hfile.puts "" } # close cppfile } # close hfile |
To use it, you specify the interface name, input header file, output file base name, and optionally whether you want logging information to be generated for each wrapped method.
For example, ruby wrapper_gen.rb IDirect3DTexture9 d3d9.h d3d9tex true would generate a wrapper for the IDirect3DTexture9 interface, get the information from d3d9.h, and store the generated wrapper on d3d9tex.h and d3d9tex.cpp. The implementations for the latter would include logging.
Here’s are the generated files for this test case.
d3d9tex.h:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
// wrapper for IDirect3DTexture9 in d3d9.h // generated using wrapper_gen.rb #include "d3d9.h" interface hkIDirect3DTexture9 : public IDirect3DTexture9 { IDirect3DTexture9 *m_pWrapped; public: hkIDirect3DTexture9(IDirect3DTexture9 **ppIDirect3DTexture9); // original interface STDMETHOD(QueryInterface)(REFIID riid, void** ppvObj); STDMETHOD_(ULONG, AddRef)(); STDMETHOD_(ULONG, Release)(); STDMETHOD(GetDevice)(IDirect3DDevice9** ppDevice); STDMETHOD(SetPrivateData)(REFGUID refguid, CONST void* pData, DWORD SizeOfData, DWORD Flags); STDMETHOD(GetPrivateData)(REFGUID refguid, void* pData, DWORD* pSizeOfData); STDMETHOD(FreePrivateData)(REFGUID refguid); STDMETHOD_(DWORD, SetPriority)(DWORD PriorityNew); STDMETHOD_(DWORD, GetPriority)(); STDMETHOD_(void, PreLoad)(); STDMETHOD_(D3DRESOURCETYPE, GetType)(); STDMETHOD_(DWORD, SetLOD)(DWORD LODNew); STDMETHOD_(DWORD, GetLOD)(); STDMETHOD_(DWORD, GetLevelCount)(); STDMETHOD(SetAutoGenFilterType)(D3DTEXTUREFILTERTYPE FilterType); STDMETHOD_(D3DTEXTUREFILTERTYPE, GetAutoGenFilterType)(); STDMETHOD_(void, GenerateMipSubLevels)(); STDMETHOD(GetLevelDesc)(UINT Level, D3DSURFACE_DESC *pDesc); STDMETHOD(GetSurfaceLevel)(UINT Level, IDirect3DSurface9** ppSurfaceLevel); STDMETHOD(LockRect)(UINT Level, D3DLOCKED_RECT* pLockedRect, CONST RECT* pRect, DWORD Flags); STDMETHOD(UnlockRect)(UINT Level); STDMETHOD(AddDirtyRect)(CONST RECT* pDirtyRect); }; |
d3d9tex.cpp:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 |
// wrapper for IDirect3DTexture9 in d3d9.h // generated using wrapper_gen.rb #include "d3d9tex.h" hkIDirect3DTexture9::hkIDirect3DTexture9(IDirect3DTexture9 **ppIDirect3DTexture9) { m_pWrapped = *ppIDirect3DTexture9; *ppIDirect3DTexture9 = this; } HRESULT APIENTRY hkIDirect3DTexture9::QueryInterface(REFIID riid, void** ppvObj) { SDLOG(20, "hkIDirect3DTexture9::QueryInterface\n"); return m_pWrapped->QueryInterface(riid, ppvObj); } ULONG APIENTRY hkIDirect3DTexture9::AddRef() { SDLOG(20, "hkIDirect3DTexture9::AddRef\n"); return m_pWrapped->AddRef(); } ULONG APIENTRY hkIDirect3DTexture9::Release() { SDLOG(20, "hkIDirect3DTexture9::Release\n"); return m_pWrapped->Release(); } HRESULT APIENTRY hkIDirect3DTexture9::GetDevice(IDirect3DDevice9** ppDevice) { SDLOG(20, "hkIDirect3DTexture9::GetDevice\n"); return m_pWrapped->GetDevice(ppDevice); } HRESULT APIENTRY hkIDirect3DTexture9::SetPrivateData(REFGUID refguid, CONST void* pData, DWORD SizeOfData, DWORD Flags) { SDLOG(20, "hkIDirect3DTexture9::SetPrivateData\n"); return m_pWrapped->SetPrivateData(refguid, pData, SizeOfData, Flags); } HRESULT APIENTRY hkIDirect3DTexture9::GetPrivateData(REFGUID refguid, void* pData, DWORD* pSizeOfData) { SDLOG(20, "hkIDirect3DTexture9::GetPrivateData\n"); return m_pWrapped->GetPrivateData(refguid, pData, pSizeOfData); } HRESULT APIENTRY hkIDirect3DTexture9::FreePrivateData(REFGUID refguid) { SDLOG(20, "hkIDirect3DTexture9::FreePrivateData\n"); return m_pWrapped->FreePrivateData(refguid); } DWORD APIENTRY hkIDirect3DTexture9::SetPriority(DWORD PriorityNew) { SDLOG(20, "hkIDirect3DTexture9::SetPriority\n"); return m_pWrapped->SetPriority(PriorityNew); } DWORD APIENTRY hkIDirect3DTexture9::GetPriority() { SDLOG(20, "hkIDirect3DTexture9::GetPriority\n"); return m_pWrapped->GetPriority(); } void APIENTRY hkIDirect3DTexture9::PreLoad() { SDLOG(20, "hkIDirect3DTexture9::PreLoad\n"); return m_pWrapped->PreLoad(); } D3DRESOURCETYPE APIENTRY hkIDirect3DTexture9::GetType() { SDLOG(20, "hkIDirect3DTexture9::GetType\n"); return m_pWrapped->GetType(); } DWORD APIENTRY hkIDirect3DTexture9::SetLOD(DWORD LODNew) { SDLOG(20, "hkIDirect3DTexture9::SetLOD\n"); return m_pWrapped->SetLOD(LODNew); } DWORD APIENTRY hkIDirect3DTexture9::GetLOD() { SDLOG(20, "hkIDirect3DTexture9::GetLOD\n"); return m_pWrapped->GetLOD(); } DWORD APIENTRY hkIDirect3DTexture9::GetLevelCount() { SDLOG(20, "hkIDirect3DTexture9::GetLevelCount\n"); return m_pWrapped->GetLevelCount(); } HRESULT APIENTRY hkIDirect3DTexture9::SetAutoGenFilterType(D3DTEXTUREFILTERTYPE FilterType) { SDLOG(20, "hkIDirect3DTexture9::SetAutoGenFilterType\n"); return m_pWrapped->SetAutoGenFilterType(FilterType); } D3DTEXTUREFILTERTYPE APIENTRY hkIDirect3DTexture9::GetAutoGenFilterType() { SDLOG(20, "hkIDirect3DTexture9::GetAutoGenFilterType\n"); return m_pWrapped->GetAutoGenFilterType(); } void APIENTRY hkIDirect3DTexture9::GenerateMipSubLevels() { SDLOG(20, "hkIDirect3DTexture9::GenerateMipSubLevels\n"); return m_pWrapped->GenerateMipSubLevels(); } HRESULT APIENTRY hkIDirect3DTexture9::GetLevelDesc(UINT Level, D3DSURFACE_DESC *pDesc) { SDLOG(20, "hkIDirect3DTexture9::GetLevelDesc\n"); return m_pWrapped->GetLevelDesc(Level, pDesc); } HRESULT APIENTRY hkIDirect3DTexture9::GetSurfaceLevel(UINT Level, IDirect3DSurface9** ppSurfaceLevel) { SDLOG(20, "hkIDirect3DTexture9::GetSurfaceLevel\n"); return m_pWrapped->GetSurfaceLevel(Level, ppSurfaceLevel); } HRESULT APIENTRY hkIDirect3DTexture9::LockRect(UINT Level, D3DLOCKED_RECT* pLockedRect, CONST RECT* pRect, DWORD Flags) { SDLOG(20, "hkIDirect3DTexture9::LockRect\n"); return m_pWrapped->LockRect(Level, pLockedRect, pRect, Flags); } HRESULT APIENTRY hkIDirect3DTexture9::UnlockRect(UINT Level) { SDLOG(20, "hkIDirect3DTexture9::UnlockRect\n"); return m_pWrapped->UnlockRect(Level); } HRESULT APIENTRY hkIDirect3DTexture9::AddDirtyRect(CONST RECT* pDirtyRect) { SDLOG(20, "hkIDirect3DTexture9::AddDirtyRect\n"); return m_pWrapped->AddDirtyRect(pDirtyRect); } |
You can adjust the code generated for the logging in the Ruby script. As you can see, this can save you a lot of rote work, particularly if you want to intercept multiple large interfaces.
Update:
The original script didn’t deal with unnamed function parameters correctly. Now it should.